درخت تصمیم (Decision Tree) یکی از ابزارها و تکنیکهایی است که در مهارتهای دادهکاوی بسیار پر کاربرد است. زمانی که حجم دادهها بسیار بالا باشد این تکنیک میتواند به کمک شما بیاید.
به وفور اتفاق میافتد که مدیران پروژه و تحلیلگران کسبوکار از این تکنیک کمک بگیرند. این تکنیک در استاندارد PMBOK نیز شرح داده شده است.
برای درک بهتر و عمیقتر درخت تصمیم لازم است ابتدا با دادهکاوی و پایگاههای داده آشنا شوید.
آشنایی با دادهکاوی و کشف دانش در پایگاههای داده
در زمان روبرو شدن با حجم عظیمی از اطلاعات یا پیچیده بودن روابط بین دادهها و نیز زمانی که دسترسی به اطلاعات نهفته میان دادهها مشکل باشد، مفهوم دادهکاوی معنا پیدا میکند. این روزها از تکنیکهای دیتاماینینگ در هوشمندسازی کسبوکار بسیار استفاده میشود. این مقاله شما را با مفهوم دادهکاوی آشنا خواهد کرد و برخی از تکنیکهای آن از جمله درخت تصمیم را فرا خواهید گرفت.
دادهکاوی یعنی چه؟
دادهکاوی و کشف دانش، استخراج دانش ناشناخته، نهان و مفید از دادههای موجود در پایگاههای داده است. با وجودی که عبارات کشف دانش و دادهکاوی معادل هم به کار میروند ولی در واقع دادهکاوی بخشی از فرآیند کشف دانش میباشد.
کاربرد دادهکاوی
برای درک بهتر کاربرد درخت تصمیم بهتر است ابتدا کاربرد دادهکاوی را درک کنید. دادهکاوی یک علم میان رشتهای است و از تلفیق علوم آمار، پایگاه داده، یادگیری ماشین و … به وجود آمده است و در تمام حوزههایی که داده و اطلاعات وجود دارد قابل کاربرد است. از جمله مدیریت، پزشکی، اقتصاد، حقوق، بازاریابی، IT، بانکداری، بورس و غیره.
روشهای دادهکاوی یا دیتامایننیگ
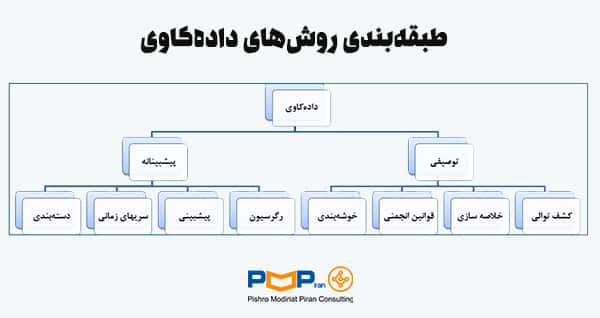
روشهای اصلی دادهکاوی به دو دسته توصیفی (Description) و پیشبینانه (Prediction) تقسیم میشوند. خوشهبندی (Clustering) از معروفترین روشهای توصیفی و دستهبندی از پر اهمیتترین روشهای پیشبینانه میباشد. شکل زیر یک نمای کلی از طبقهبندی روشهای دادهکاوی را نمایش میدهد.
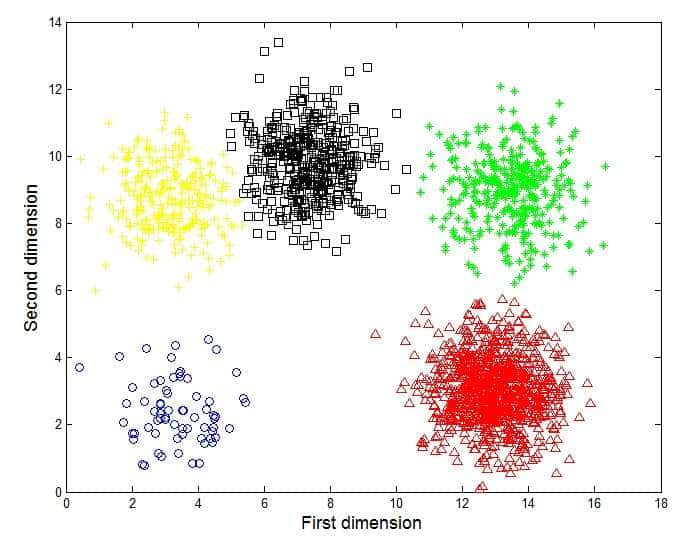
در روش خوشهبندی، دادهها بر اساس اصل حداکثر کردن شباهت داخل گروهها و حداقل کردن شباهت بین گروهها، خوشهبندی یا گروهبندی میشوند مانند شکل زیر. مثال خوشهبندی میتواند کشف زیرگروههای همگن مصرفکنندگان در یک پایگاه دادههای بازاریابی باشد.
دستهبندی، فرایند یافتن مدلی است که با تشخیص دستهها یا مفاهیم داده میتواند دسته ناشناخته اشیاء دیگر را پیشبینی کند. دستهبندی یک تابع یادگیری است که یک قلم داده را به یکی از دستههای از قبل تعریف شده نگاشت میکند.
برخی روشهای متداول دستهبندی عبارتند از درخت تصمیم، دستهبندی بیزی، شبکه عصبی (Neural Network) که در مطالب دیگری در وبلاگ PMPiran به آنها خواهیم پرداخت.
درخت تصمیم یا Decision Tree
یکی از پرکاربردترین الگوریتمهای دادهکاوی، الگوریتم درخت تصمیم است. در دادهکاوی، درخت تصمیم یک مدل پیشبینی کننده است به طوری که میتواند برای هر دو مدل رگرسیون و طبقهای مورد استفاده قرار گیرد. زمانی که درخت برای کارهای طبقهبندی استفاده میشود، به عنوان درخت طبقهبندی (Classification Tree) شناخته میشود و هنگامی که برای فعالیتهای رگرسیونی به کار میرود درخت رگرسیون (Regression Decision Tree)نامیده میشود.
درختهای طبقهبندی برای طبقهبندی یک مجموعه رکورد به کار میرود. به صورت رایج در فعالیتهای بازاریابی، مهندسی و پزشکی استفاده میشود.
در ساختار درخت تصمیم، پیشبینی به دست آمده از درخت در قالب یک سری قواعد توضیح داده میشود. هر مسیر از ریشه تا یک برگ درخت تصمیم، یک قانون را بیان میکند و در نهایت برگ با کلاسی که بیشترین مقدار رکورد در آن تعلق گرفته برچسب میخورد.
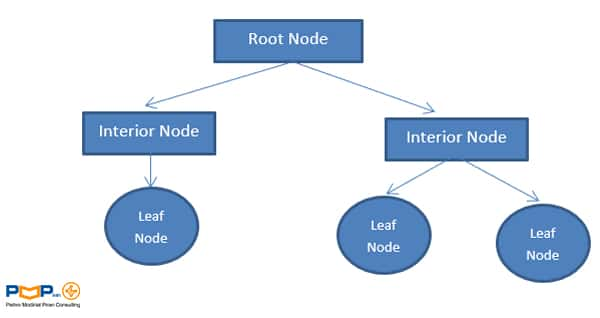
اجزای اصلی درخت تصمیم
برگ (Leaf Nodes): گرههایی که تقسیمهای متوالی در آنجا پایان مییابد. برگها با یک کلاس مشخص میشوند.
ریشه (Root Node): منظور از ریشه، گره آغازین درخت است.
شاخه (Branches): در هر گره داخلی به تعداد جوابهای ممکن شاخه ایجاد میشود.
معیارهای انتخاب مشخصه برای انشعاب درخت تصمیم
یک معیار انتخاب مشخصه، یک ابتکار برای انتخاب معیار نقطه انشعاب است به طوری که بهترین تفکیک دادههای آموزش را به کلاسهای برچسبدار داشته باشد.
سه معیار انتخاب مشخصه شناخته شده عبارتند از:
- Information gain
- Gain ratio
- Gini index
هرس کردن درخت تصمیم
هرس کردن درخت تصمیم مقابل عمل تقسیم کردن است و با هرس کردن زیر گرههایی در درخت تصمیم حذف میگردد. زمانی که یک درخت تصمیم ساخته میشود، تعدادی از شاخهها ناهنجاریهایی در دادههای آموزش منعکس میکنند که ناشی از دادههای پرت و یا نویز است.
در برخی الگوریتمهای ایجاد درخت، هرس کردن جزئی از الگوریتم محسوب میشود. در حالی که در برخی دیگر، تنها برای رفع مشکل بیش برازش از هرس کردن استفاده میشود.
چندین روش، معیارهای آماری را برای حذف کمتر شاخههای قابل اطمینان به کار میبرند. درختهای هرس شده تمایل به کوچکتر بودن و پیچیدگی کمتر دارند و بنابراین به راحتی قابل فهم میباشند. آنها معمولا در طبقهبندی صحیح دادههای تست سریعتر و بهتر از درختهای هرس نشده عمل میکنند.
دو رویکرد رایج برای هرس درخت به شرح ذیل وجود دارد:
- پیشهرس (Pre pruning)
در این رویکرد یک درخت به وسیله توقفهای مکرر در مراحل اولیه ساخت درخت، هرس میشود. به محض ایجاد یک توقف گره به برگ تبدیل میشود.
- هرس پسین (Post pruning)
رویکرد هرس پسین درخت تصمیم رایجتر است به این صورت که زیر درختها از یک درخت رشد یافته کامل را حذف میکند. یک زیر درخت در یک گره به وسیله حذف کردن شاخهها و جایگزینی آنها با یک برگ، هرس میشود.
اندازه درخت
درخت تصمیم که پیچیدگی کمتری داشته باشد قابل بیان و روشن است. بنابراین پیچیدگی درخت تاثیر مهمی بر روی صحت آن میگذارد.
معمولا پیچیدگی درخت توسط یکی از معیارهای زیر اندازهگیری میشود:
- تعداد کل گرهها
- تعداد کل برگها
- عمق درخت و تعداد مشخصههای به کار رفته
پیچیدگی درخت به وسیله معیار توقف و روشهای هرس کردن به راحتی کنترل میشود.
الگوریتمهای شایع برای برقراری درخت تصمیم
- ID3
یکی از الگوریتمهای بسیار ساده درخت تصمیم که در سال ۱۹۸۶ توسط Quinlan مطرح شده است. اطلاعات به دست آمده به عنوان معیار تفکیک به کار میرود. این الگوریتم هیچ فرایند هرس کردن را به کار نمیبرد و مقادیر اسمی و مفقوده را مورد توجه قرار نمیدهد.
- C4.5
این الگوریتم درخت تصمیم، تکامل یافته ID3 است که در سال ۱۹۹۳ توسط Quinlan مطرح شده است.
Gain Ratio به عنوان معیار تفکیک در نظر گرفته میشود. عمل تفکیک زمانی که تمامی نمونهها پایین آستانه مشخصی واقع میشوند، متوقف میشود. پس از فاز رشد درخت عمل هرس کردن بر اساس خطا اعمال میشود. این الگوریتم مشخصههای اسمی را نیز در نظر میگیرد.
- CART
برای برقراری درختهای رگرسیون و دستهبندی از این الگوریتم استفاده میشود. در سال 1984توسط Breiman و همکارانش ارائه شده است. نکته حائز اهمیت این است که این الگوریتم درختهای باینری ایجاد میکند به طوری که از هر گره داخلی دو لبه از آن خارج میشود و درختهای بدست آمده توسط روش اثربخشی هزینه، هرس میشوند.
یکی از ویژگیهای این الگوریتم، توانایی در تولید درختهای رگرسیون است. در این نوع از درختها برگها به جای کلاس مقدار واقعی را پیشبینی میکنند. الگوریتم برای تفکیک کنندهها، میزان مینیمم مربع خطا را جستجو میکند. در هر برگ، مقدار پیشبینی بر اساس میانگین خطای گرهها میباشد.
- CHID
این الگوریتم درخت تصمیم به جهت در نظرگرفتن مشخصههای اسمی در سال ۱۹۸۱ توسط Kass طراحی شده است. الگوریتم برای هر مشخصه ورودی یک جفت مقدار که حداقل تفاوت را با مشخصه هدف داشته باشد، پیدا میکند.
ارزیابی مدل
هنگامی که یک دستهبندی کننده ساخته میشود، اندازهگیری صحت آن دارای اهمیت زیادی است. برای اندازهگیری صحت یک دستهبندیکننده بهتر است از دادههای تست استفاده شود. یعنی پس از ساخت مدل روی دادههای آموزشی، میزان صحت مدل در تعیین برچسب کلاس نمونهها، روی دادههای تست مورد آزمایش قرار گیرد.
صحت یک دستهبندی کننده روی نمونههای آزمایشی برابر تعداد نمونههایی است که به درستی توسط مدل، دستهبندی شدهاند. البته میتوان به جای صحت، نرخ خطا را نیز محاسبه نمود.
مزایای درخت تصمیم
- درخت تصمیم بدیهی است و نیاز به توصیف ندارد.
- هر دو مشخصه اسمی و عددی را میتواند مورد توجه قرار دهد.
- نمایش درخت تصمیم به اندازه کافی برای نشان دادن هرگونه طبقهبندی غنی است.
- مجموعه دادههایی که ممکن است دارای خطا باشند را در نظر میگیرد.
- مجموعه دادههایی که دارای مقادیر مفقوده هستند را شامل میشود.
- درختهای تصمیم روشهای ناپارامتری را نیز مورد توجه قرار میدهد.
علاوه بر نقاط قوت اشاره شده، درخت تصمیم نیاز به محاسبات پیچیده برای دستهبندی دادهها ندارد. همچنین درخت تصمیم نشان میدهد که کدام مشخصه تاثیر بیشتری در دستهبندی دارند.
یک نمونه درخت تصمیم
نمونه درخت تصمیم در حوزه پزشکی:
درخت زیر تشخیص بی اختیاری ادراری زنان با مشخصههای کلینیکی و سیستوسکوپی را نشان میدهد. این درخت تصمیم، مدل “تصمیم یار تشخیص بی اختیاری ادراری زنان” نامیده شده است.
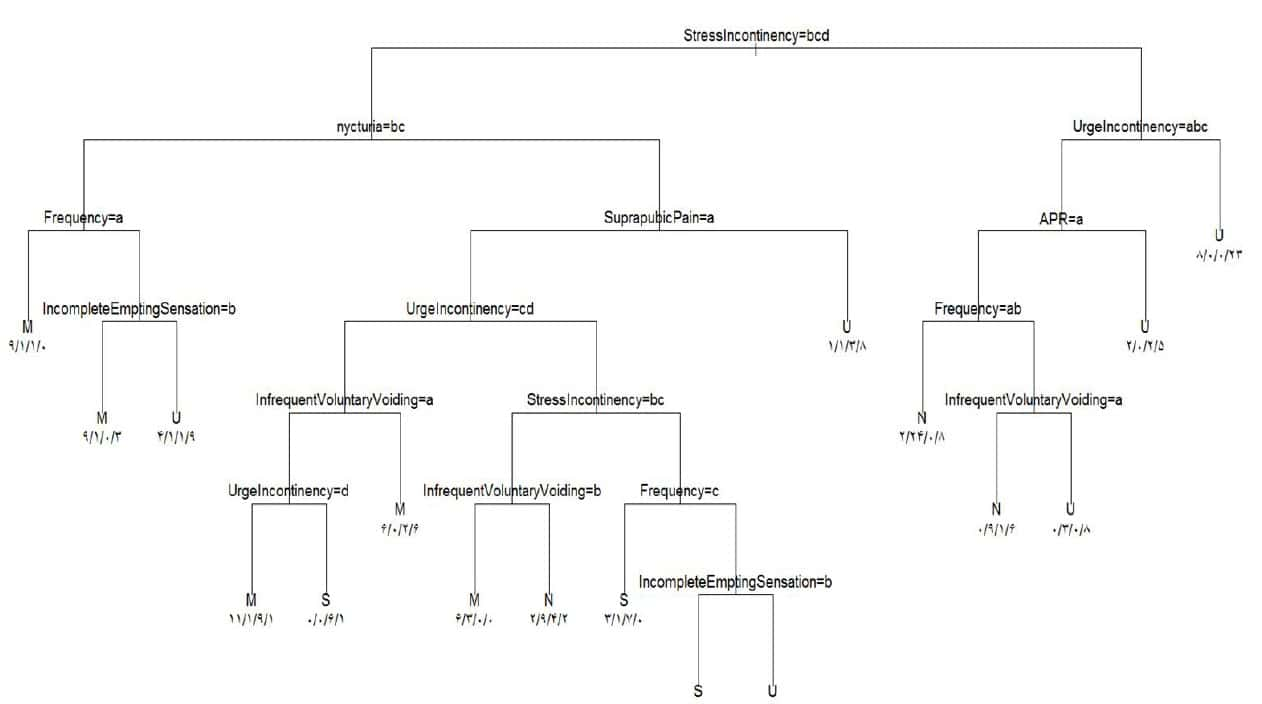
قواعد استخراج شده از درخت تصمیم فوق
- IF Stress Incontinency: a & Urge Incontinency : d THEN Type of Incontinence: U
- IF Stress Incontinency: a & Urge Incontinency : a b c & APR : b THEN Type of Incontinence: U
- IF Stress Incontinency: a& Urge Incontinency : a b c & APR : a &Frequency: a b THEN Type of Incontinence: N
- IF Stress Incontinency: a & Urge Incontinency : a b c & APR : a &Frequency: c & Infrequent Voluntary Voiding: b THEN Type of Incontinence: U
- IF Stress Incontinency: a & Urge Incontinency : a b c & APR : a &Frequency: c & Infrequent Voluntary Voiding: a THEN Type of Incontinence: N
- IF Stress Incontinency: b c d & nycturia: b c & Frequency : a THEN Type of Incontinence : M
- IF Stress Incontinency: b c d & nycturia: b c & Frequency : b c & Incomplete Empting Sensation: b THEN Type of Incontinence: M
- IF Stress Incontinency: b c d & nycturia: b c & Frequency : b c & Incomplete Empting Sensation: a THEN Type of Incontinence: U
- IF Stress Incontinency: b c d & nycturia: a d & Suprapubicpain: b THEN Type of Incontinence: U
- IF Stress Incontinency: b c d & nycturia: a d & Suprapubicpain: a & Urge Incontinency :c d & Infrequent Voluntary Voiding :b THEN Type of Incontinence: M
- IF Stress Incontinency: b c d & nycturia: a d & Suprapubicpain: a & Urge Incontinency :d & Infrequent Voluntary Voiding :a THEN Type of Incontinence: M
- IF Stress Incontinency: b c d & nycturia: a d & Suprapubicpain: a & Urge Incontinency :c & Infrequent Voluntary Voiding :a THEN Type of Incontinence: S
- IF Stress Incontinency: b c & nycturia: a d & Suprapubicpain: a & Urge Incontinency: a b & Infrequent Voluntary Voiding :b THEN Type of Incontinence: M
قابل ذکر است برای حل مساله فوق از نرم افزار R استفاده شده است.
پرکاربردترین نرمافزارهای درخت تصمیم
زمانیکه بخواهید از نرمافزار برای دستهبندی نمونهها به روش الگوریتم درخت تصمیم استفاده کنید میتوانید از نرمافزارهای زیر بهرهمند شوید.
- R
- SPSS Modeler
- MATLAB
- SAS JMP
- Clementine
- Python
برای مطالعات بیشتر
با مطالعه مقالات زیر میتوانید در مورد دادهکاوی، درخت تصمیم و نرمافزار R اطلاع بیشتری کسب کنید.
Chapman, Hall . (2010).”Data Mining with R Learning with Case Studies” , Luis Torgo. LIACC-FEP , University of Porto. R. Campo Alegre, 823 – 4150.
Han, Jiawei ., Kamber, Micheline. (2006). “Data Mining: Concepts and Techniques”, Morgan Kaufmann Publishers,2.
جمعبندی
مفهوم درخت تصمیم به طور کامل به همراه جزئیات آن در این مقاله توضیح داده شد. اگر دادهها دارای شرایط منطقی هستند یا به دستههای مختلف گسسته می شوند، الگوریتم درخت تصمیم انتخاب درستی است. اگر دادهها دارای متغیرهای عددی بیش از حد هستند، بهتر است الگوریتمهای طبقهبندی دیگر استفاده شود. درخت تصمیم باعث میشود که در مهارتهای تصمیمگیری خود احساس اطمینان کنید تا بتوانید با موفقیت تیم خود را رهبری کنید و پروژهها را مدیریت کنید. به شما پیشنهاد میکنیم تا برای ارتقای مهارتها و کسب دانش مورد نیاز مدیریت پروژه در دوره جامع مدیریت پروژه دانشگاه امیرکبیر شرکت کنید. در این دوره علاوه بر ارتقاء مهارتها، یک پروژه را تا پایان دوره به صورت عملی انجام خواهید داد که باعث آشنایی بیشتر شما با فضای حاکم بر پروژه میشود.






دیدگاهتان را بنویسید